The Evolution of React Rendering Architectures & Web Performance
 Photo by Mulyadi
Photo by MulyadiIn this post, we'll see how different rendering architectures work. We'll talk about Client-Side Rendering (CSR), Server-Side Rendering (SSR), and Streaming SSR in React and how they impact performance on the web.
First of all, how do we measure performance on the web? The current standard is the core web vitals (take a look at the web performance research for more info). These metrics are:
- LCP: Largest Contentful Paint — measures the time it takes to render the main content
- FID: First Input Delay — measures the latency of the first interaction a user has made with the page
- CLS: Cumulative Layout Shift — measures the stability of the page
But we'll also talk about other complementary performance metrics in this article. They are:
- TTFB: Time To First Byte — measures the connection setup time and server responsiveness
- FCP: First Contentful Paint — measures the time it takes to render the first content
- INP: Interaction to Next Paint — measures the latency of all interactions a user has made with the page
- TTI: Time To Interactive - measures the time at which a page becomes interactive (events wired up, etc).
With that context in mind, we dive deep into the rendering architectures and how each impacts the performance of a web app.
CSR — Client Side Rendering
As the name suggests, CSR renders the content on the client. It means JavaScript will handle how the page is rendered, but how does it work?
A common approach, perhaps popularized by create-react-app, is the “single-page application”. It has a very thin layer of HTML, a file that has only the head, a body with a div (where the content is going to be placed), and the script tag, which will be responsible to make the browser download, parse, and execute the JavaScript bundle. While running JavaScript, React.js can render all related DOM nodes on the browser.
This is what it usually looks like:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>Undefined</title>
</head>
<body>
<div id="root"></div>
<script src="/app.js" type="text/javascript"></script>
</body>
</html>
This is the backbone of a Client-Side Rendering architecture. A small HTML file with the basic stuff and ready to make the browser uses JavaScript to render the actual content.
This is how it works under the hood:
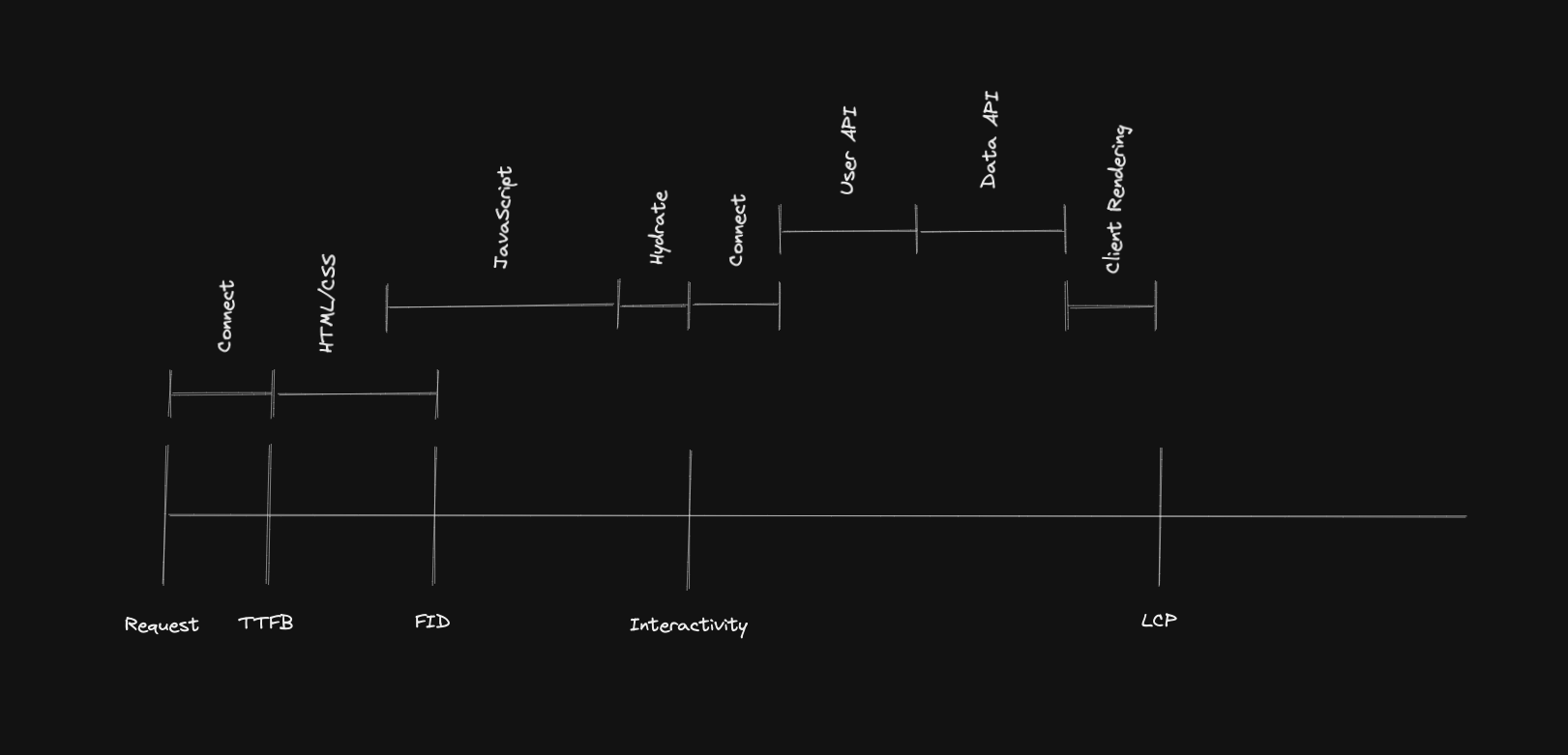
These are the steps of a CSR architecture:
- The client (browser) sends a request
- Connection happens
- A minimal HTML/CSS is rendered
- Scripts tags are executed: JavaScript files downloaded, parsed, and executed
- Hydration: making the website interactive
- Fetching data: it can be requested to any API — user API to get user data, content API (e.g. itinerary data if it's a hotel app, products data if it's an e-commerce kind of app)
- Rendering happens and the content is rendered on the page (LCP will be measured only here, probably)
Here we can see Client-Side Rendering has issues in some of these steps and because of them, it can translate into bad performance.
The most problematic part is the need for browsers to download, parse, and execute the generated bundle and only then be able to fetch the data and finally render the content on the page.
- The browser on the client handles the execution of JavaScript
- The browser on the client handles data fetching
- Rendering on the client happens only after JavaScript is executed and data fetching is done
The time it takes to handle this whole process is relied on the user's device. If it's more powerful and the internet connection is good, browsers can handle it well with a certain limit. It can be a huge performance bottleneck if the device is less powerful or the connection is not good (3g or worse).
It's challenging to optimize LCP on a CSR application as it needs to have all these steps one after another to finally render the LCP element.
The time between the start of JavaScript download to rendering the LCP can be huge, in some cases, it can even reach 16s on mobile 4g. Even if you optimize the application with code-splitting and browser caching, it's challenging to get better Core Web Vitals (CWV). The problem increases the bigger your final bundle is. The more your application's bundle size increases, the more you hurt the final users’ experience.
“CSR cannot get good performance as measured by Core Web Vitals (CWV). SSR / SSG can, but it's not a guarantee. If good performance is important in your use-case then you will need to move beyond CSR.” — Dan Shappir
Some of the benefits of Client-Side Rendering is that it doesn't really need a server to handle the application. You can easily setup the app and serve it on a CDN. Depending on how the app is structured and implemented, it has soft navigations which provide a better UX. But if performance is a bottleneck and is hurting the final user, we should think of a better architecture.
SSR — Server-Side Rendering
Different than Client-Side Rendering, SSR handles rendering on the server, so everything (data fetching, generated HTML, etc) is done on the server and not on the client anymore. This is how it works under the hood:
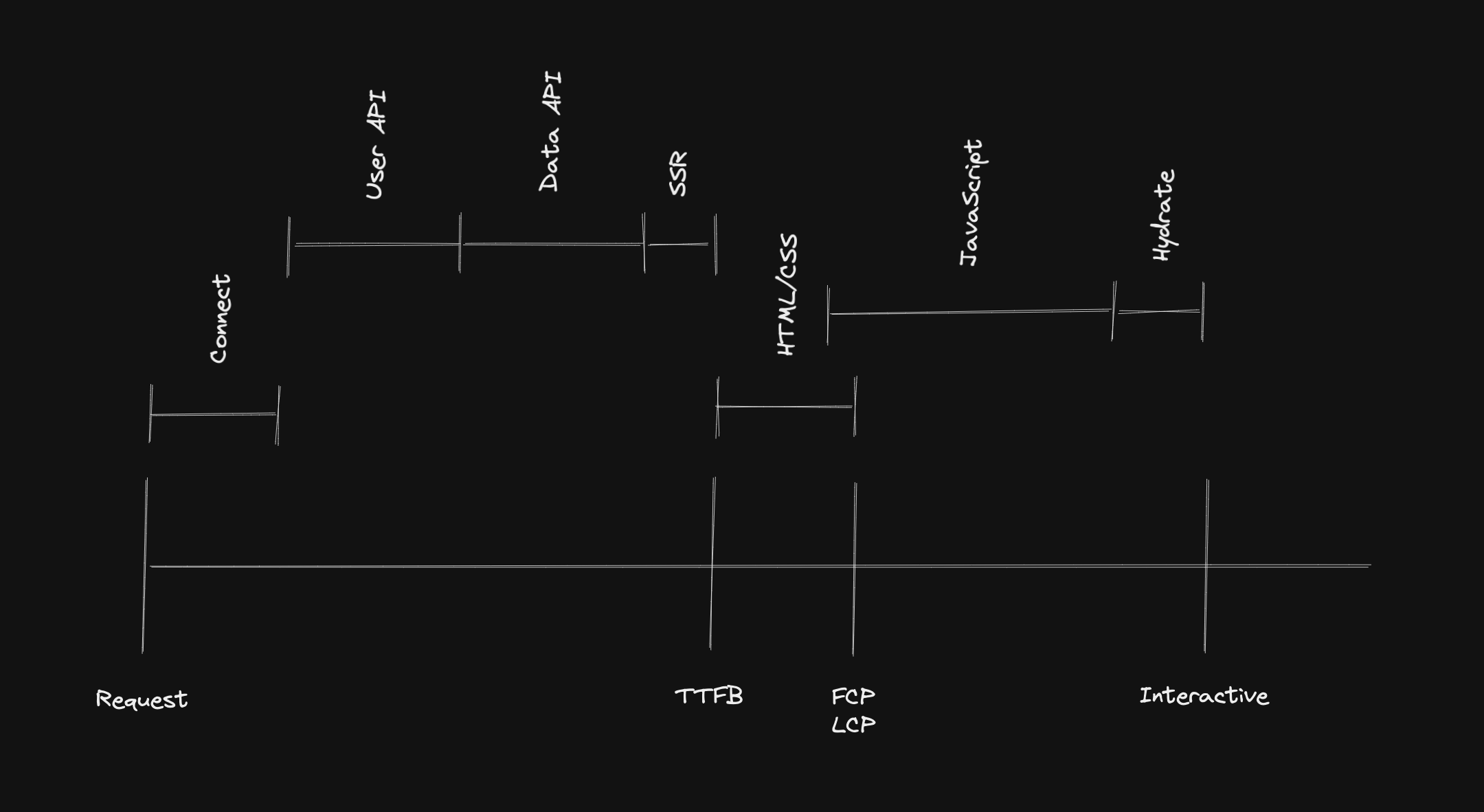
These are the SSR steps:
- On the server
- Fetch data for the entire app: user data, content data
- Render the entire app to HTML and send it in the response
- On the client
- Load the JavaScript code for the entire app
- Hydration: Connect the JavaScript logic to the server-generated HTML for the entire app
This part is important: each step has to finish before the next step can start. There’s no concurrency/parallelism here. This means it begins with data fetching, then generate the HTML, renders the HTML on the client, loads the JavaScript bundle, and then hydrates the app. In this order, no parallelism.
The performance gain is in these particular parts:
- Data fetching happens on the server. With a more powerful machine, it handles this process faster than when it's done on the client, which relies on the user's device
- SSR: generates HTML from react components on the server and sends that HTML to the client
- As the page is already generated, the user can see the content before loading the JavaScript bundle.
The server handles data fetching and the generation of static HTML and responds to the client's request pretty fast compared to what's done in Client-Side Rendering.
An interesting piece of info about data fetching is:
- Server-side data fetching can be faster than client-side data fetching, particularly for large datasets or complex queries. This is because servers often have more resources available than client devices, such as more processing power, memory, and faster internet connections.
- After the request is sent, we have the TTFB or the time it needs to wait for the server response and the content download (resource)
- TTFB: 1 roundtrip of latency and the time the server took to prepare the response. It relies on the server (in this case, SAPI) to respond to the website
- Content download: the total amount of time reading the response body. It relies on the machine (servers vs. browsers/user devices)
Because of these facts, SSR can hugely improve the performance metrics of your application.
To back it up, we have interesting case studies on the CSR → SSR migration and how it impacted performance:
- Optimizing Core Web Vitals on a Next.js app — reported 73% and 51% improvements for FCP and LCP, respectively when migrating the app to Next.js SSR.
- Dan Shappir - The Challenges and Pitfalls of Server Side Rendering — reported 60% improvements on Time to visible (it’s similar to Start render and FCP metrics)
- Improving The Performance Of Wix Websites (Case Study) — Smashing Magazine — reported an improvement from 17.55s to 2.55s in rendering the complete page. It doesn’t rely only on SSR though.
But, as we saw, SSR also has some performance bottlenecks. It needs to wait for the entire app to fetch the data to be able to render the HTML. And it needs to do a whole DOM hydration. Some would say Hydration is a Pure Overhead and for others SSR was never the problem. The problem was, and still is, the client-side hydration.
This can be a big problem for interactivity metrics like FID (First Input Delay) and INP (Interaction to Next Paint).
What if we could be more granular about which parts of HTML we can flush rather than flush the entire HTML just once? We would flush smaller, granular chunks over time.
- Static parts are rendered from the server without the need to wait for the data to be fetched (first flush)
- Parts of the UI that are still waiting for the data to be fetched can render a loading indicator (spinner, skeleton)
- and when the fetch is done, the server streams again (second flush) the missing (dynamic) parts.
That’s called Streaming SSR and it's what we are going to see next.
Streaming SSR
Streaming is all about parallelizing operations. The idea is to send HTML in chunks and progressively render it as it's received. So, we can parallelize work on the server and send small HTML chunks over time to the client.
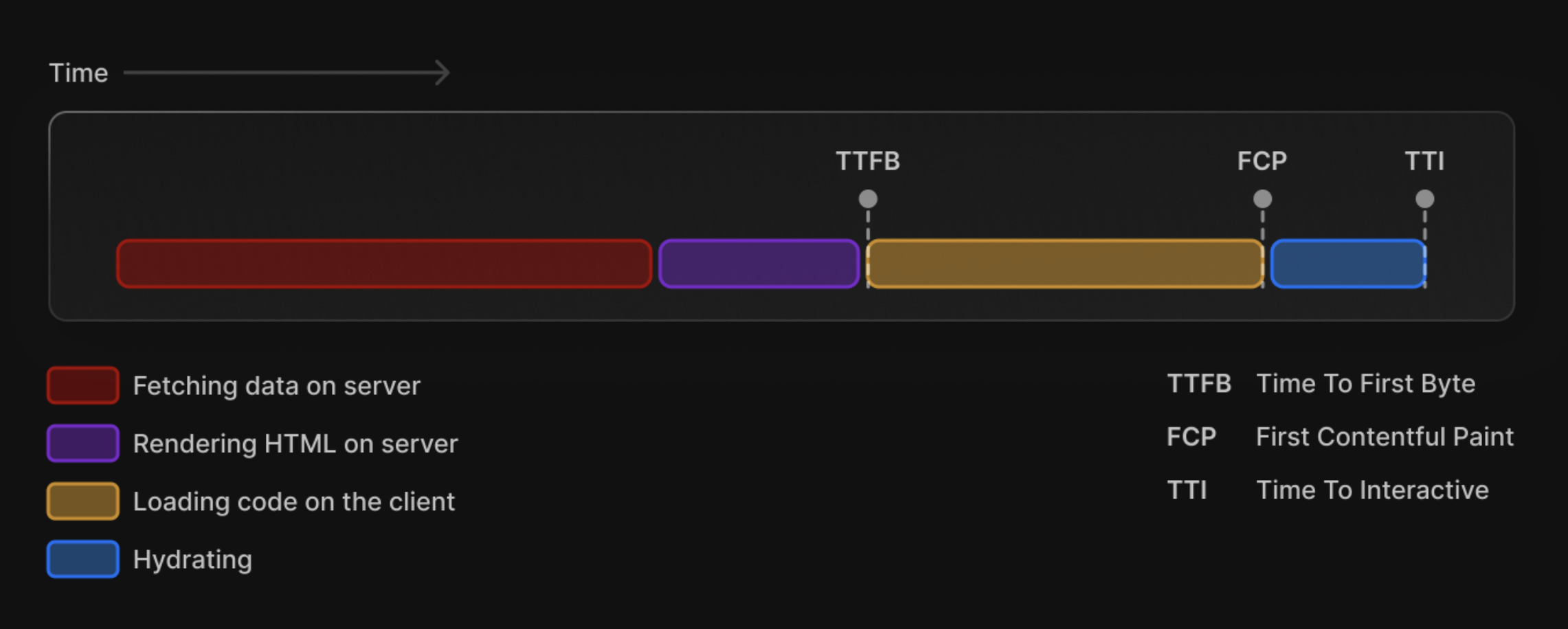
With that in mind, we can solve, or at least improve the two major problems of SSR:
- Rendering on the server is blocked by data: it needs to wait for data fetching to be finished to respond to the request and render on the client, which offers a slower TTFB
- Hydration is a bottleneck: making the website interactive depends on JavaScript, so the browser needs to download, parse, and execute JS before hydrating the entire page, making TTI (and other interactivity metrics like FID and INP) worse
Streaming SSR tackles these two problems. Now that SSR can rely on Streams, we can send granular, smaller chunks of HTML to the client. Before it was blocked by data fetching, now we can render the “static” parts first while the server handles data fetching. So, rendering the first HTML chunk is pretty fast, which improves TTFB and FCP for the app.
Then, when SSR finishes the data fetching, it can stream the second HTML chunk to the client. We now clearly draw the line between static HTML and HTML that relies on data fetching. But we can make it even more granular. If we have parts of the page that relies on different data, we can divide them into N pieces of HTML chunks and stream them back to the client whenever they're ready to be rendered.
We all know hydration is a big performance bottleneck when it comes to SSR and Streaming SSR tries to fix/improve this problem by using something called Selective Hydration.
SSR can stream HTML in chunks over time, so each HTML chunk delivered and rendered on the client can be hydrated right away. It doesn't need to wait for the second and the following chunks to be rendered.
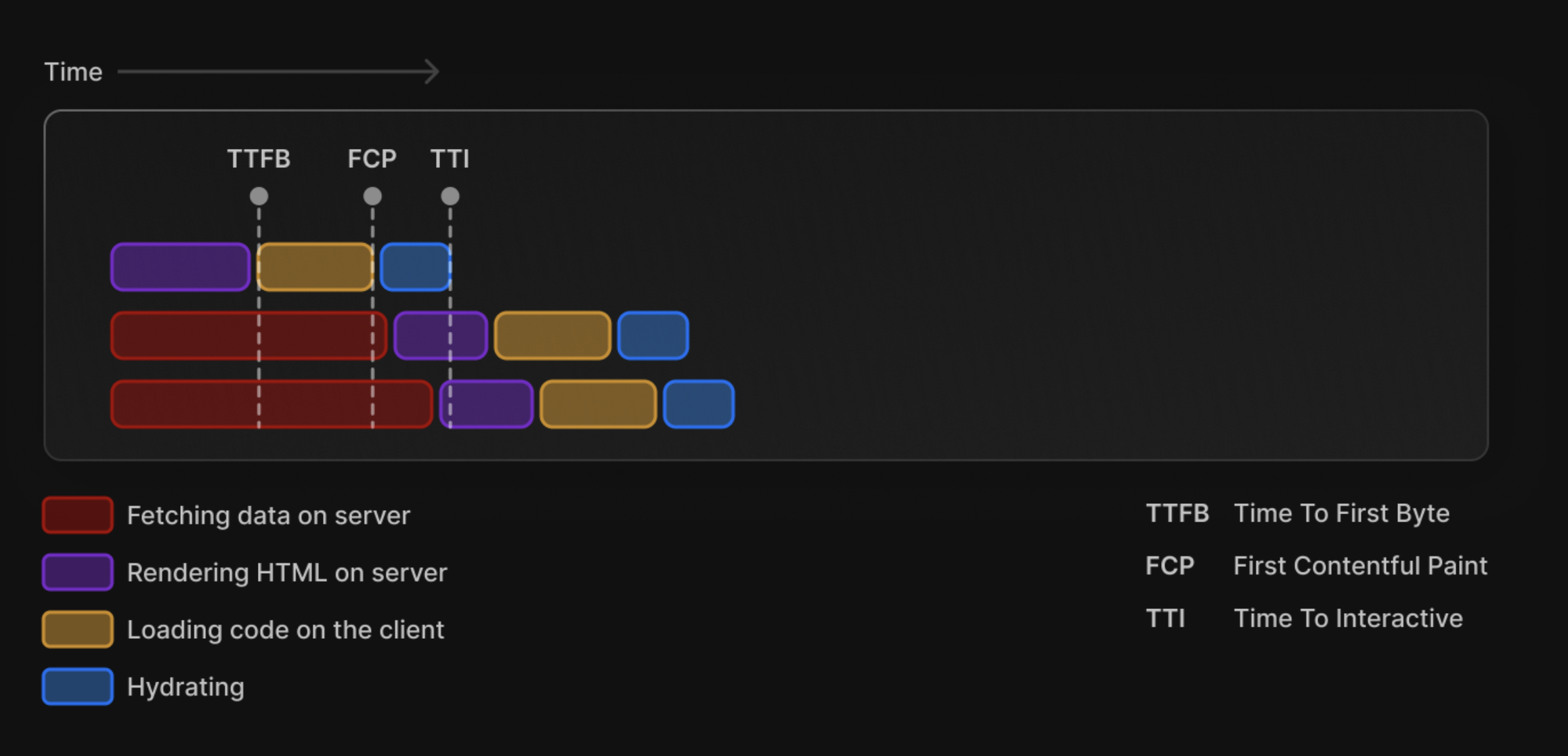
Imagine we took a strategy of dividing the HTML into 3 chunks:
- static chunk
- dynamic chunk relied on fetching an API (fetch #1)
- dynamic chunk relied on another API (fetch #2)
While fetch #1 and fetch #2 are running, the static chunk can be delivered to the client. When the browser receives it, it gets rendered and it starts hydrating this selected part (selective hydration!). Let's say fetch #1 finishes first. It gets rendered and hydrated on the client without the need to wait for fetch #2 to be finished. And then, fetch #2 gets rendered and hydrated after its related data is fetched.
You can see that everything is now parallelized. But keep in mind that it has a caveat here. When each chunk gets to the browser, for it to be rendered and hydrated, the main thread needs to be free to handle the work. If it's busy, there's no way it gets worked on, unless it gets prioritized.
Parallelizing hydration (with Selective Hydration), we get better TTI (and FID and INP) compared to “pure” SSR.
So, in general, with Streaming SSR, we get:
- Parallelized server rendering HTML in smaller chunks
- Selective hydration for each streamed HTML chunk
- Better TTFB and FCP because of the smaller HTML chunk streamed
- Better TTI, FID, and INP because of selective hydration of the smaller chunks
In terms of implementation, we use a nice abstraction called “React Suspense”.
Let's think about an example to illustrate how this would work. Imagine an e-commerce.

- An e-commerce has a logo, a search bar, an avatar, filters, and a list of products
- We can organize the components into “static” and “dynamic”
- Dynamic components are components that rely on data fetching like the products list and the avatar
- And the Static components are the ones that don't rely on data fetching and can just render the HTML right away, like all components besides the list of products and the avatar
This is how it would look like in a “pure” SSR (or even a CSR) implementation:
<Layout>
<Header>
<Logo />
<SearchBar />
<Avatar />
<Header>
<Filters />
<Products />
</Layout>
It's an “all or nothing” approach. It needs to fetch the User API for the data to the <Avatar /> component and the Products API for the data to the <Products /> component before rendering and hydrating everything.
The Streaming SSR with the Suspense boundary would look like this:
<Layout>
<Header>
<Logo />
<SearchBar />
<Suspense fallback={<AvatarSkeleton />}>
<Avatar />
</Suspense>
<Header>
<Filters />
<Suspense fallback={<ProductsSkeleton />}>
<Products />
</Suspense>
</Layout>
While the data fetching for the user and the products are running on the server, everything besides the <Avatar /> and the <Products /> components will be rendered. For <Avatar /> and <Products /> the server will fall back to the placeholder. In this case, they are skeleton loaders.

And then the client can already work on the hydration of the components rendered on the browser while the data fetching is still running on the server. It doesn't need to wait for the data fetching to be finished.

And finally, when the data fetch is done, the products and the avatar are rendered and hydrated on the client.

With this approach, we can now render the static parts of the page running the data requests in parallel. It can also use Selective Hydration to handle the hydration of these static parts. It doesn't need to wait for anything else.
When the data is ready, the server can stream back the HTML and it will be rendered and hydrated on the client.
All this with a simple abstraction called Suspense.
It's important to notice that Suspense is not a feature exclusive to Streaming SSR. Suspense is a mechanism to show a fallback for a certain part of the application while it's waiting for the data. When the data is ready, the fallback UI (spinners, skeletons) will be updated with the actual content. So it can also be used in Client-Side Rendering.
Performance impact on the web
There's a collection of interesting performance case studies, and here I list ones that talk about rendering architectures and how they optimized performance for their app.
- Optimizing Core Web Vitals on a Next.js app — reported 73% and 51% improvements for FCP and LCP, respectively when migrating the app to Next.js SSR.
- Dan Shappir - The Challenges and Pitfalls of Server Side Rendering — reported 60% improvements on Time to visible (it’s similar to Start render and FCP metrics)
- Improving The Performance Of Wix Websites (Case Study) — Smashing Magazine — reported an improvement from 17.55s to 2.55 in rendering the complete page. It doesn’t rely only on SSR though.
- How QuintoAndar increased conversion rates and pages per session by improving page performance — 39% improvement on LCP & 39% improvement on TTI
Resources
Rendering Architecture
- The Future (and the Past) of the Web is Server Side Rendering
- The Benefits of Server Side Rendering Over Client Side Rendering
- What Is Server-side Rendering And How Does It Improve Site Speed?
- Streaming server-side rendering (SSR)
- Rendering on the Web
- Advanced Rendering Patterns
React
- New Suspense SSR Architecture in React 18
- Partial Hydration
- The future of rendering in React
- Suspense: React Doc
- Suspense and Error Boundaries in React 18
- When To Fetch: Remixing React Router
- A guide to streaming SSR with React 18
- Streaming and Suspense
Web Performance
- Web Performance Research
- Optimizing Core Web Vitals on a Next.js app
- Dan Shappir - The Challenges and Pitfalls of Server Side Rendering
- Improving The Performance Of Wix Websites (Case Study) — Smashing Magazine
- How QuintoAndar increased conversion rates and pages per session by improving page performance