Publisher, a tooling to automate the process to publish my blog posts
 Photo by Glenn Carstens-Peters
Photo by Glenn Carstens-PetersAs I'm building a writing habit, well, I'm writing more and more. Even though I use publishing blogs like Medium, dev.to, and Hashnode, I like to post my content on my own blog.
As I wanted to build a simple website, this blog is basically an HTML, CSS with very little JavaScript website. But the thing is, the publishing process could be a lot better.
How does it work now?
I manage the blog roadmap on Notion. It looks like this:
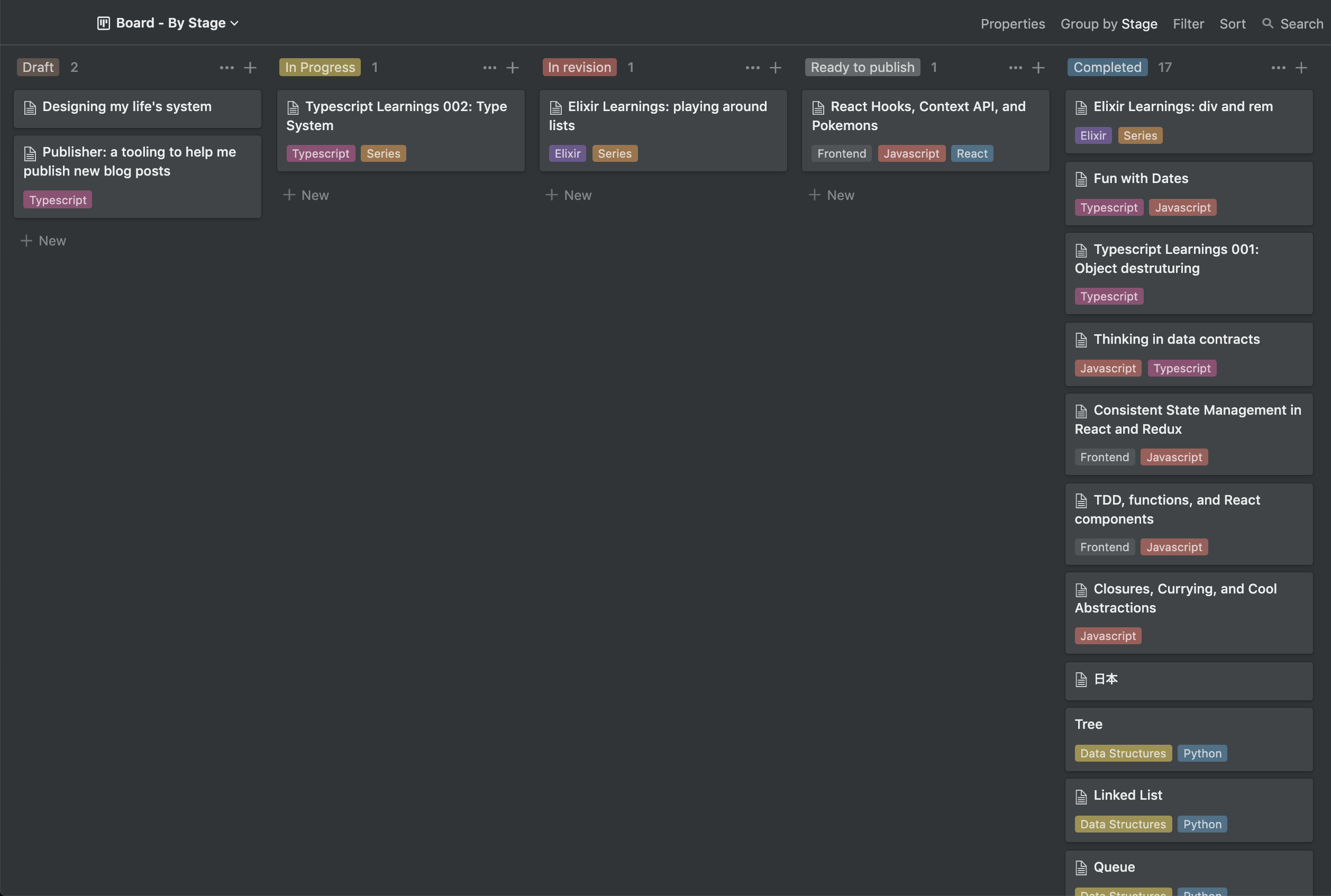
It's a simple kanban type of board. I like this board because I can get all my ideas into physical (or digital?) representation. I also use it to build a draft, polish and make it better and better to publish in the blog.
So I write my blog post using Notion. After I finish it, I copy the Notion writing and paste it into an online tool to transform markdown into HTML. And then I can use this HTML to create the actual post.
But this is just the body, the content for the page. I always need to create the whole HTML with the head content, body, and footer.
This process is tedious and boring. But good news, it can be automated. And this post is all about this automation. I want to show you the behind the scenes of this new tool I created and the learnings I got through this process.
Features
My main idea was to have a whole HTML article ready to publish. As I mentioned before, the <head> and <footer> sections don't change much. So I could use it as a "template".
With this template, I have the data that could change for each article I would write and publish. This data could be a variable in the template with this representation {{ variableName }}. An example:
<h1>{{ title }}</h1>
Now I can use the template and replace the variables with real data, specific info for each article.
The second part is the body, the real post. In the template, it is represented by {{ article }}. This variable will be replaced by the HTML generated by Notion markdown.
When we copy and paste notes from Notion, we get kind of a Markdown style. This project will transform this markdown into an HTML and use it as the article variable in the template.
To create the ideal template, I took a look of all variables I needed to create:
titledescriptiondatetagsimageAltimageCoverphotographerUrlphotographerNamearticlekeywords
With these variables, I created the template.
To pass some of this information to build the HTML, I created a json file as the article config: article.config.json. There I have something like this:
{
"title": "React Hooks, Context API, and Pokemons",
"description": "Understanding how hooks and the context api work",
"date": "2020-04-21",
"tags": ["javascript", "react"],
"imageAlt": "The Ash from Pokemon",
"photographerUrl": "<https://www.instagram.com/kazuh.illust>",
"photographerName": "kazuh.yasiro",
"articleFile": "article.md",
"keywords": "javascript,react"
}
First step: the project should know how to open and read the template and the article config. With this data, I could use to populate the template.
Template first:
const templateContent: string = await getTemplateContent();
So we basically need to implement the getTemplateContent function.
import fs, { promises } from 'fs';
import { resolve } from 'path';
const { readFile } = promises;
const getTemplateContent = async (): Promise<string> => {
const contentTemplatePath = resolve(__dirname, '../examples/template.html');
return await readFile(contentTemplatePath, 'utf8');
};
The resolve with __dirname will get the absolute path to the directory from the source file that is running. And then go to the examples/template.html file. The readFile will asynchronously read and return the content from the template path.
Now we have the template content. And we need to do the same thing for the article config.
const getArticleConfig = async (): Promise<ArticleConfig> => {
const articleConfigPath = resolve(
__dirname,
'../examples/article.config.json',
);
const articleConfigContent = await readFile(articleConfigPath, 'utf8');
return JSON.parse(articleConfigContent);
};
Two different things here:
- As the
article.config.jsonhas a json format, we need to transform this json string into an JavaScript object after reading the file - The return of the article config content will be an
ArticleConfigas I defined in the function return type. Let's build it.
type ArticleConfig = {
title: string;
description: string;
date: string;
tags: string[];
imageCover: string;
imageAlt: string;
photographerUrl: string;
photographerName: string;
articleFile: string;
keywords: string;
};
When we get this content, we also use this new type.
const articleConfig: ArticleConfig = await getArticleConfig();
Now we can use the replace method to fill the config data in the template content. Just to illustrate the idea, it would look like this:
templateContent.replace('title', articleConfig.title);
But some variables appear more than one time in the template. Regex for the rescue. With this:
new RegExp('\\{\\{(?:\\\\s+)?(title)(?:\\\\s+)?\\}\\}', 'g');
... I get all the strings that match {{ title }}. So I could build a function that receives a parameter to be found and use it in the title place.
const getPattern = (find: string): RegExp =>
new RegExp('\\{\\{(?:\\\\s+)?(' + find + ')(?:\\\\s+)?\\}\\}', 'g');
Now we can replace all matches. An example for the title variable:
templateContent.replace(getPattern('title'), articleConfig.title);
But we don't want to replace only the title variable, but all variables from the article config. Replace all!
const buildArticle = (templateContent: string) => ({
with: (articleConfig: ArticleAttributes) =>
templateContent
.replace(getPattern('title'), articleConfig.title)
.replace(getPattern('description'), articleConfig.description)
.replace(getPattern('date'), articleConfig.date)
.replace(getPattern('tags'), articleConfig.articleTags)
.replace(getPattern('imageCover'), articleConfig.imageCover)
.replace(getPattern('imageAlt'), articleConfig.imageAlt)
.replace(getPattern('photographerUrl'), articleConfig.photographerUrl)
.replace(getPattern('photographerName'), articleConfig.photographerName)
.replace(getPattern('article'), articleConfig.articleBody)
.replace(getPattern('keywords'), articleConfig.keywords),
});
Now I replace all! We use it like this:
const article: string = buildArticle(templateContent).with(articleConfig);
But we are missing two parts here:
tagsarticle
In the config json file, the tags is a list. So, for the list:
['javascript', 'react'];
The final HTML would be:
<a class="tag-link" href="../../../tags/javascript.html">javascript</a>
<a class="tag-link" href="../../../tags/react.html">react</a>
So I created another template: tag_template.html with the {{ tag }} variable. We just need to map the tags list and create each HTML tag template.
const getArticleTags = async ({
tags,
}: {
tags: string[];
}): Promise<string> => {
const tagTemplatePath = resolve(__dirname, '../examples/tag_template.html');
const tagContent = await readFile(tagTemplatePath, 'utf8');
return tags.map(buildTag(tagContent)).join('');
};
Here we:
- get the tag template path
- get the tag template content
- map through the
tagsand build the final tag HTML based on the tag template
The buildTag is a function that returns another function.
const buildTag =
(tagContent: string) =>
(tag: string): string =>
tagContent.replace(getPattern('tag'), tag);
It receives the tagContent - it is the tag template content - and returns a function that receives a tag an build the final tag HTML. And now we call it to get the article tags.
const articleTags: string = await getArticleTags(articleConfig);
About the article now. It looks like this:
const getArticleBody = async ({
articleFile,
}: {
articleFile: string;
}): Promise<string> => {
const articleMarkdownPath = resolve(__dirname, `../examples/${articleFile}`);
const articleMarkdown = await readFile(articleMarkdownPath, 'utf8');
return fromMarkdownToHTML(articleMarkdown);
};
It receives the articleFile, we try to get the path, read the file, and get the markdown content. Then pass this content to fromMarkdownToHTML function to transform the markdown into an HTML.
This part I'm using an external library called showdown. It handles every little corner case to transform markdown into HTML.
import showdown from 'showdown';
const fromMarkdownToHTML = (articleMarkdown: string): string => {
const converter = new showdown.Converter();
return converter.makeHtml(articleMarkdown);
};
And now I have the tags and the article HTML:
const templateContent: string = await getTemplateContent();
const articleConfig: ArticleConfig = await getArticleConfig();
const articleTags: string = await getArticleTags(articleConfig);
const articleBody: string = await getArticleBody(articleConfig);
const article: string = buildArticle(templateContent).with({
...articleConfig,
articleTags,
articleBody,
});
I missed one more thing! Before, I expected that I always needed to add the image cover path into the article config file. Something like this:
{
"imageCover": "an-image.png"
}
But we could assume that the image name will be cover. The challenge was the extension. It can be .png, .jpg, .jpeg, or .gif.
So I built a function to get the right image extension. The idea is to search for the image in the folder. If it exists in the folder, return the extension.
I started with the "existing" part.
fs.existsSync(`${folder}/${fileName}.${extension}`);
Here I'm using the existsSync function to find the file. If it exists in the folder, it returns true. Otherwise, false.
I added this code into a function:
const existsFile =
(folder: string, fileName: string) =>
(extension: string): boolean =>
fs.existsSync(`${folder}/${fileName}.${extension}`);
Why did I do this way?
Using this function, I need to pass the folder, the filename, and the extension. The folder and the filename are always the same. The difference is the extension.
So I could build a function using curry. That way, I can build different functions for the same folder and filename. Like this:
const hasFileWithExtension = existsFile(examplesFolder, imageName);
hasFileWithExtension('jpeg'); // true or false
hasFileWithExtension('jpg'); // true or false
hasFileWithExtension('png'); // true or false
hasFileWithExtension('gif'); // true or false
The whole function would look like this:
const getImageExtension = (): string => {
const examplesFolder: string = resolve(__dirname, `../examples`);
const imageName: string = 'cover';
const hasFileWithExtension = existsFile(examplesFolder, imageName);
if (hasFileWithExtension('jpeg')) {
return 'jpeg';
}
if (hasFileWithExtension('jpg')) {
return 'jpg';
}
if (hasFileWithExtension('png')) {
return 'png';
}
return 'gif';
};
But I didn't like this hardcoded string to represent the image extension. enum is really cool!
enum ImageExtension {
JPEG = 'jpeg',
JPG = 'jpg',
PNG = 'png',
GIF = 'gif',
}
And the function now using our new enum ImageExtension:
const getImageExtension = (): string => {
const examplesFolder: string = resolve(__dirname, `../examples`);
const imageName: string = 'cover';
const hasFileWithExtension = existsFile(examplesFolder, imageName);
if (hasFileWithExtension(ImageExtension.JPEG)) {
return ImageExtension.JPEG;
}
if (hasFileWithExtension(ImageExtension.JPG)) {
return ImageExtension.JPG;
}
if (hasFileWithExtension(ImageExtension.PNG)) {
return ImageExtension.PNG;
}
return ImageExtension.GIF;
};
Now I have all the data to fill the template. Great!
As the HTML is done, I want to create the real HTML file with this data. I basically need to get the correct path, the HTML, and use the writeFile function to create this file.
To get the path, I needed to understand the pattern of my blog. It organizes the folder with the year, the month, the title, and the file is named index.html.
An example would be:
2020/04/publisher-a-tooling-to-blog-post-publishing/index.html
At first, I thought about adding this data to the article config file. So every time I need to update this attribute from the article config to get the correct path.
But another interesting idea was to infer the path by some data we already have in the article config file. We have the date (e.g. "2020-04-21") and the title (e.g. "Publisher: tooling to automate blog post publishing").
From the date, I can get the year and the month. From the title, I can generate the article folder. The index.html is always constant.
The string would like this:
`${year}/${month}/${slugifiedTitle}`;
For the date, it is really simple. I can split by - and destructure:
const [year, month]: string[] = date.split('-');
For the slugifiedTitle, I built a function:
const slugify = (title: string): string =>
title
.trim()
.toLowerCase()
.replace(/[^\\w\\s]/gi, '')
.replace(/[\\s]/g, '-');
It removes the white spaces from the beginning and the end of the string. Then downcase the string. Then remove all special characters (keep only word and whitespace characters). And finally, replace all whitespaces with a -.
The whole function looks like this:
const buildNewArticleFolderPath = ({
title,
date,
}: {
title: string;
date: string;
}): string => {
const [year, month]: string[] = date.split('-');
const slugifiedTitle: string = slugify(title);
return resolve(__dirname, `../../${year}/${month}/${slugifiedTitle}`);
};
This function tries to get the article folder. It doesn't generate the new file. This is why I didn't add the /index.html to the end of the final string.
Why did it do that? Because, before writing the new file, we always need to create the folder. I used mkdir with this folder path to create it.
const newArticleFolderPath: string = buildNewArticleFolderPath(articleConfig);
await mkdir(newArticleFolderPath, { recursive: true });
And now I could use the folder the create the new article file in it.
const newArticlePath: string = `${newArticleFolderPath}/index.html`;
await writeFile(newArticlePath, article);
One thing we are missing here: as I added the image cover in the article config folder, I needed to copy it and paste it into the right place.
For the 2020/04/publisher-a-tooling-to-blog-post-publishing/index.html example, the image cover would be in the assets folder:
2020/04/publisher-a-tooling-to-blog-post-publishing/assets/cover.png
To do this, I need two things:
- create a new
assetsfolder withmkdir - copy the image file and paste it into the new folder with
copyFile
To create the new folder, I just need the folder path. To copy and paste the image file, I need the current image path and the article image path.
For the folder, as I have the newArticleFolderPath, I just need to concatenate this path to the assets folder.
const assetsFolder: string = `${newArticleFolderPath}/assets`;
For the current image path, I have the imageCoverFileName with the correct extension. I just need to get the image cover path:
const imageCoverExamplePath: string = resolve(
__dirname,
`../examples/${imageCoverFileName}`,
);
To get the future image path, I need to concatenate the image cover path and the image file name:
const imageCoverPath: string = `${assetsFolder}/${imageCoverFileName}`;
With all these data, I can create the new folder:
await mkdir(assetsFolder, { recursive: true });
And copy and paste the image cover file:
await copyFile(imageCoverExamplePath, imageCoverPath);
As I was implementing this paths part, I saw I could group them all into a function buildPaths.
const buildPaths = (newArticleFolderPath: string): ArticlePaths => {
const imageExtension: string = getImageExtension();
const imageCoverFileName: string = `cover.${imageExtension}`;
const newArticlePath: string = `${newArticleFolderPath}/index.html`;
const imageCoverExamplePath: string = resolve(
__dirname,
`../examples/${imageCoverFileName}`,
);
const assetsFolder: string = `${newArticleFolderPath}/assets`;
const imageCoverPath: string = `${assetsFolder}/${imageCoverFileName}`;
return {
newArticlePath,
imageCoverExamplePath,
imageCoverPath,
assetsFolder,
imageCoverFileName,
};
};
I also created the ArticlePaths type:
type ArticlePaths = {
newArticlePath: string;
imageCoverExamplePath: string;
imageCoverPath: string;
assetsFolder: string;
imageCoverFileName: string;
};
And I could use the function to get all the path data I needed:
const {
newArticlePath,
imageCoverExamplePath,
imageCoverPath,
assetsFolder,
imageCoverFileName,
}: ArticlePaths = buildPaths(newArticleFolderPath);
The last part of the algorithm now! I wanted to quickly validate the created post. So what if I could open the created post in a browser tab? That would be amazing!
So I did it:
await open(newArticlePath);
Here I'm using the open library to simulate the terminal open command.
And that was it!
Learnings
This project was a lot of fun! I learned some cool things through this process. I want to list them here:
- As I'm learning Typescript, I wanted to quickly validate the code I was writing. So I configured
nodemonto compile and run the code on every file save. It is cool to make the development process so dynamic. - I tried to use the new node
fs'spromises:readFile,mkdir,writeFile, andcopyFile. It is onStability: 2. - I did a lot of currying for some function to make it reusable.
- Enums and Types are good ways to make the state consistent in Typescript, but also make a good representation and documentation of all the project's data. Data contracts is a really nice thing.
- The tooling mindset. This is one of the things I really love about programming. Build toolings to automate repetitive tasks and make life easier.
I hope it was good reading! Keep learning and coding!