DX & Software Maintainability in Frontend Engineering
 Photo by Ryan Ancill
Photo by Ryan AncillIn the last quarter, I was assigned a big project to work on. Our main goal was to understand the biggest problems and technical challenges we have in our current frontend application and build a thorough vision of how we can move forward.
I've been doing a lot of work on frontend engineering and backend for frontend (BFF) applications and I had an accumulated experience of what problems I could work on. But before start executing (like crazy!), I wanted to make the goal clear and set principles for that project.
Goals
Improve and enable better user and developer experience
This role gave me a lot of autonomy to execute the project in my own way. I liked the idea of balancing execution (improve) and exploration (enable).
DX and UX are one of the core principles I followed to act on the most impactful challenges. Improving DX makes our engineers move faster, increase their productivity to work on business projects, and ship products without (much) friction. Improving DX also can enable better UX as engineers are moving fast to ship product features, find bugs and easily fix them and focus more on the business part of coding.
Build a vision and how we can move forward
For this specific project I worked "alone", I didn't have a squad, but a group of people I could use their support. Thinking about that, it would be impossible to organize my time to explore the problems and technical opportunities and execute everything.
Big challenges require time and effort. As people in the tech industry usually say: "Software development is a team sport". My goal was not to get some time to solve all problems but to show possible solutions, understand the effort needed to execute these solutions, and build a vision to show how we can move forward.
The vision can be built in a documentation format. But part of my goal was also to create space to discuss, build the culture, and enforce the ideas in our actions while building software.
Principles
"Engineering principles realize our values in concrete concepts and guide everyone in a fair and structured way." - Ilya Kozlov
- Root for simplicity
- Work on what matters
- Share knowledge & Transparency
"Simplicity is prerequisite for reliability." - Edsger W. Dijkstra
All these principles are interconnected to the work I did in this project. To reduce the system's complexity, I needed to always think of the simplest way to (re)build the software. When striving for simplicity, we ease our understanding of the software, making it easier to maintain, because it's simpler to change, debug, and refactor.
So, simpler systems have a real impact on the developer experience and productivity. And this is really connected to the "work on what matters". I could start refactoring all code I wanted, but it could have little or no impact on the developer's productivity. Focusing on the developer experience that enables better user experience was my goal and a great variable when thinking in prioritization of what I should work on.
As a "one-person team", I understood that if I really wanted to have a real impact in the organization, I needed a better way to scale the knowledge and the vision. From day 0, I had a Notion page representing the project with everything I was doing documented: backlog, meeting notes, goal & principles, weekly report. Transparency and accessibility were part of the vision I wanted to build with this project together with incremental knowledge sharing throughout the entire quarter.
Starting up
Before start working on this project, I worked on other 4 different products at QuintoAndar. They were all different in terms of business contexts and clients, but very similar when it comes to tech stack and technical challenges.
Over time, I noticed the similarities and started to document the same technical debts, reimagining future architectures, building abstractions that could be reused across the organization, proposing new ways to handle data contracts and consistent state management, build tools to improve DX, etc.
They were all frontend engineering challenges I encountered on my way by building different products. It was a good starting point to have these initial ideas in my backlog to start exploring. But it was very limited.
I also start sketching the engineer's workflow:
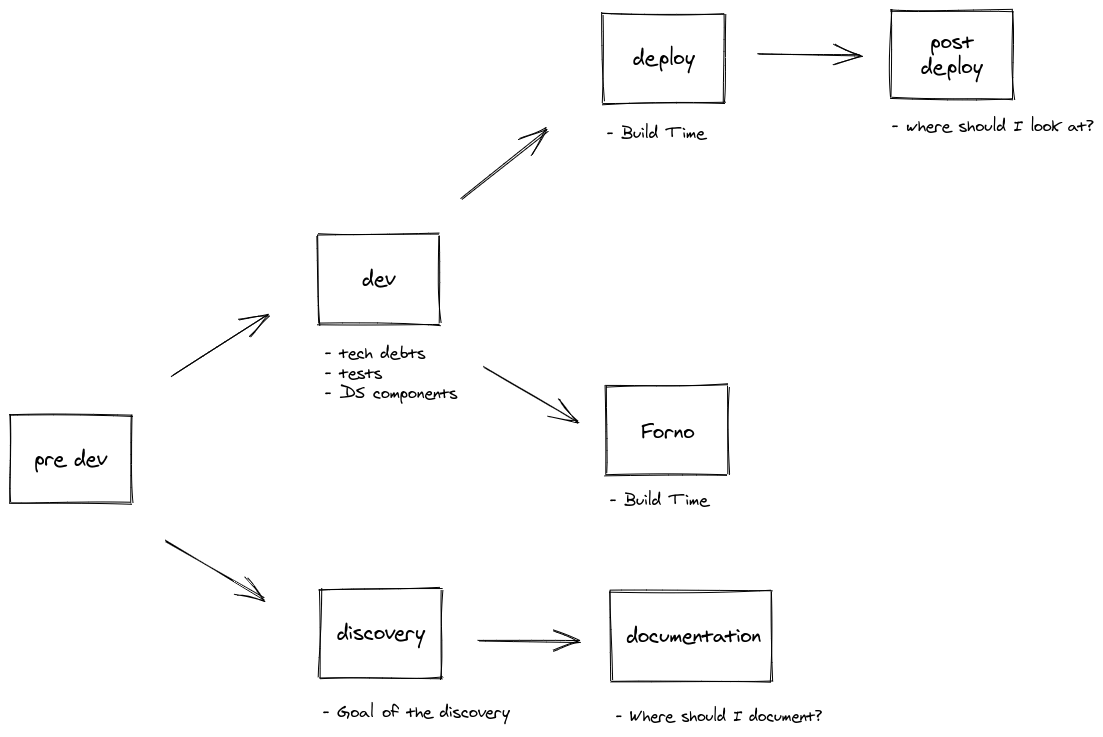
From getting the Jira ticket to deploy and taking a look at the monitoring system, we had a lot of opportunities to improve and make the dev experience awesome. It's great to have the big picture's vision, but I also wanted to focus on another powerful tool: listening!
"Listening through questions is a form of active listening with the goal of understanding the rest of the room's perspectives" - @lethain
To improve the developer experience, I needed to understand the real problems the engineers were facing, so I scheduled a brainstorming meeting. In this meeting, I explained my project and shared a Metro Retro board to write down all issues our application had at that time, what was the bad DX we had, and doubts related to this application (e.g. how do we handle data fetching?; how do we handle error handling?; how do we know if our application is health?).
With all these ideas - actually, "issues" - I could organize, improve, and prioritize my backlog.
Besides those issues, one thing that came to my mind was that I (and the team) needed to be able to refactor a lot of code to improve the software quality and pay tech debts.
To enable refactoring, I added 2 "tasks" to my backlog:
- Frontend Testing: how should we test frontend & add tests to make our team more confident when deploying new features.
- App Monitoring: as an organization, we have many different tooling that could help us monitor our application. I wanted an easy way to answer three questions:
- Is the application health?
- How to use tools to help us debug bugs?
- I deployed a new feature, where should I look at?
Tests
"Quality must be enforced, otherwise it won't happen. We programmers must be required to write tests, otherwise we won't do it." - Yegor Bugayenko
Together with the Quality Assurance team, we add a lot of integration tests using Cypress to the most important workflows in the PWA. Running these integration tests in our CI for each Pull Request helped us a lot in having the confidence to ship features, refactorings, and dependencies upgrades.
I was also working on some studies related to component tests with the testing-library. Our codebase was heavily using Enzyme for most of the tests we have for React components. As we wanted to test more user behavior instead of the component structure, we started to replace Enzyme and add testing-library kinds of tests for new features and components.
As we didn't have much experience nor knowledge of the best way of how to use it, I started learning it, writing tests as examples, document all my learning, and improving our test setup.
I started writing simple recipes to use the testing-library and about testing-driven development in React. Then I wrote tests for different use cases: query elements, expecting content, user behavior (click, focus, etc), custom hooks, better setup for components using redux.
The idea behind this was to make the tests very easy to implement and improve all the pain points. This study's final result was a set of tests as examples and a wiki in our Github project to guide How to test the frontend that covers integration tests, custom hooks, component tests, using the redux store, etc.
Monitoring & Observability
"Originally the feedback loop was you would break stuff, people would yell at you, and then they would praise you when you fixed it, but then the Internet became a thing and our systems got more complicated.”
Our old way to deploy was creating Github release tags. With all these tests I mentioned earlier, we had the confidence to change the release tag to deploy on PR merge. Now we are running full CI/CD.
For the monitoring systems, we had a lot of different possibilities, but we are using mostly Sentry to make the most out of the error tracings to find bugs, debug, and fix them. We are also using Instana to keep up with the API endpoints the PWA uses. Together with the product manager, we consistently take a look at the Amplitude trackings to make sure our users can use our product
Disclaimer: Amplitude is definitely not a tracing tool, but it's nice to keep up with the user's behavior and see some weekly patterns to find issues.
One of our users' worst experiences in our application is when they are using the product and a drawer (our error boundary) shows that they had an error.
To make it distinct in the Sentry logs, we added the "fatal" level for these errors that occurs and trigger the Error Boundary (drawer). When shipping a new feature, we can look at this kind of error by filtering by level fatal.
Now we have toolings to help us verify the health of our systems. But this project aimed to improve the developer experience and I wanted to reduce the cognitive load even more, so I created a Github wiki with all the important links for the Sentry, Instana, and Amplitude dashboards.
Before, the engineers would need to open each dashboard and make their own queries, but now it's easy to access the most important metrics we want to see: open the Github wiki and they are all there.
Foundation & Tooling
"We want everything we offer to be easy to adopt. The simpler a tool or workflow is to adopt and use.. so that our users have a great out-of-box experience." - Lei Zhang
Formatting
The codebase lacked formatting consistency. We were using only eslint to lint the code and break the build process if it finds any lint error. But each engineer has their own code style, so the codebase starts to become very inconsistent.
Now we are using a code formatter called Prettier, it's an opinionated formatter, and all our codebase and PRs are consistent. We can focus on the business part of development and code reviews instead of being distracted by the format issues.
We also had a problem that we pushed code to the github remote and the eslint break the build. To avoid breaking only in the build process, we break it as fast as possible to have no need to wait for the CI build.
Now we are using husky to run eslint in each commit's changed files and format with prettier in the pre-commit. It helped us be more productive and fix things faster and before pushing to github.
I had one learning experience while adopting Prettier for legacy software to run prettier. My first idea was to scale the prettier use for each PR, but it was not a good experience because sometimes the engineer only needs to fix a line of code, but prettier would format the entire file and make it really difficult to code review.
PR Template
The Pull Request template was a bit outdated so I did a revamp to have only the necessary things to create a new PR. It's not required, but we have a description section, type of change, a checklist to help engineers be aware of all technical details we need to take a look at before shipping a new feature, and screenshots if needed.
Performance tooling
My latest project was very related to web performance (I also wrote about this experience: Optimizing the Performance of a React Progressive Web App). But I was only using lab metrics. I wanted to start collecting metrics related to real users as well. This would enable us to see if we have any performance issues for our users and tackle that problem.
We have an internal tool to handle the RUM (Real User Metrics), so I set up the tooling our PWA to start collecting these metrics. And also started to measure the navigation between pages. One of our main users flows is house registration, so adding navigation metrics would have a huge impact if we find any issue and fix it.
Dependencies
"We strive to maintain minimalism and clarity to drive development to completion." - Suckless Philosophy
Minimizing software bloat and rooting for simplicity and minimalism in software was my way to improve the dev experience. In the JavaScript ecosystem, it is very common to have a dozen different libraries that do the same things and other dozens that are borning daily. It's also usual to have many packages in a JavaScript project, even if it isn't really used or replaced with a smaller library or implemented in-house.
I started to explore all the dependencies, which ones I should take a closer look at, which ones I could upgrade and would enable new possibilities for us, and which ones I could just remove.
I could remove a ton of libraries that were not actually being used and it also pointed me to some old and dead code, they were basically features that were not being used by users or dead components that were there in the codebase. Overall, I could remove 10,200 lines of code.
Some other big packages like webpack, babel, and immutable were in my backlog to plan how I could upgrade everything. At that time, we had a team working close to the immutable removal (we're striving to not use any library or immer if an engineer prefers), so I let this library to their team to work on. And we also had a team experimenting with NextJS in some projects, so bumping webpack and babel could not be worthy, so I make this task less of a priority at that time.
Other libraries that upgraded would improve our dev experience and enable us to use interesting APIs like TypeScript and react-redux.
Bumping react-redux enabled us to use hooks together with redux, removing all the mapStateToProps and mapDispatchToProps boilerplates. Even though we are moving away from Redux (testing out react-query for server cache and hooks for client state), the codebase is heavily using it to handle state. Using hooks together with Redux became simpler to handle state and reduced the need for a lot of boilerplate code.
We don't use TypeScript heavily in our codebase yet, but upgrading it to 3.9 was easy and enabled us to use any new features from it mainly in the interface between our frontend and our backend for frontend (BFF).
Work on what matters
"To build scalable and maintainable frontend systems, we need a strategy for managing and organizing the complexity that exists in the user interface." - Safia Abdalla
Listening to the team that was heavily working on this codebase, I could understand some parts that had a lot of complexity that I could work on to make simpler and improve the developer productivity and experience.
House Registration and Edition complexity
In this codebase, we have the house registration flow for landlords, but the code modules were reused for the edition flow as well. In the beginning, it started with good intentions to reuse the same abstraction, but over time it became more and more complex and coupled.
The number of if statements were the first thing that pointed me to this problem. The second was related to the consistency of bugs that was happening in this flow. With the increase of complexity, the tests (manually and automated) didn't cover everything, it was very easy to add features that could break any part of this flow in the product.
"With great complexity comes great bugs and even greater maintenance burdens." - Safia Abdalla
Separating the modules and reusing only the components and some auxiliary helpers would reduce the complexity of each module. I created a migration strategy document organized in "Problems", "Architecture", and the "Plan" to execute it.
Bringing clarity to the team about the vision and how we could solve this problem was the first step to execute the migration. Making everyone understand the problems and the steps to refactor help scale the migration. Every person that would touch that code, could look at it with new eyes and refactor it if possible.
We are still in the process to finish the refactoring, but now we have an optimistic vision that we'll incrementally solve this problem and improve the developer experience.
DDD Architecture
In frontend applications, it's not that common to follow Domain-Driven Design, but in our context, we started to rethink our applications and how we could make them more organized and easy to reason about.
The current state of our PWAs is using components and containers folders to organize shared components and pages. Some helper functions were in big utils files or folders, which became difficult to find and reuse.
The first step was to understand what were domains
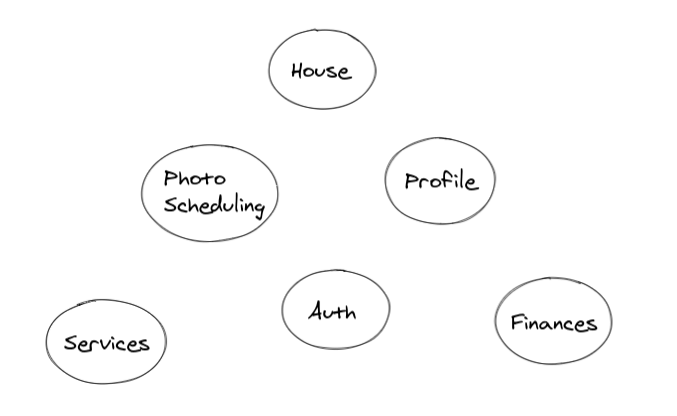
This was the first draft of the domain I designed looking at the product and the codebase. For each domain, I added a simple description to make it clear to everyone what was each one.
The same way I did for the registration and edition modules split, I did for this DDD Architecture: create a document to illustrate the problem I was solving, the vision, and the strategy to make it happen.
To make it very clear, I mapped each file/folder in the codebase to the new architecture in the document. It was not an exhaustive mapping, but it brought a lot of clarity to start refactoring the codebase.
Among all explorations I did, this is the one that we could really do incrementally over time without the need to stop everything and focus on that for 2 weeks. This is why I started to refactored it to bring some examples on how to it and scale the knowledge to every engineer in the team.
Interface between backend and frontend
One of the goals for the future is to have a layer between the PWA and the OwnerappAPI to make the data consistent using TypeScript.
We are experimenting with TypeScript in our Backend for Frontend (BFF) to have better and explicit types for each payload. And also in the frontend. I've been studying TypeScript and got to understand the real benefits of applying it to the state part of the frontend application, but also in the UI part by replacing the PropTypes with "compile-time" types.
It's an initial thought yet, but an idea is to have a common repository of types to reuse it between the PWA and the BFF. With this package of types, we can make the interface really consistent. But at the same time, we can add a level of bureaucracy that makes us slower in shipping features. It's a tradeoff that we need to think about before implementing it. But this is just an idea for the future.
Owner Landing Page DX Issue
To give context, we have a different kind of development when talking about our landing pages. We use React to develop them, but we have tooling that removes the react code and library in build time.
Every time we want to test if the landing page is correct - in terms of UI and functionality - we need to run the build process or push the new feature to the test environment, which takes about 18 minutes. Even though we have a "static" landing page without React, the developer experience was suboptimal.
This was actually an issue brought by all engineers that worked in this codebase last quarter. We knew the pain that was to build new features for landing pages.
It started as an exploration to think about which solutions I could come up with. We could work with a static site generator like 11ty, but we only have a design system for React application. This would increase the complexity to rebuild the entire landing page and make space to design inconsistencies.
Another approach was to use NextJS in the project as the default framework and serve the landing pages with SSR. The last approach was to split the landing page from the main application and use NextJS from scratch. This last approach was very interesting for us because the landing page is a living thing that many teams can work on and it shouldn't be coupled with the rest of the application. This strategy would also decrease the build time for each PR and production deployment as we didn't need to run the tests, lint, and build tool for the landing page in the application's CI build.
In this exploration, I also created a document with all possible solutions, the effort and time we needed to rebuild this landing page, the tradeoffs, and the steps for each solution.
Error Handling & Data Fetching
Most of the errors we handle for each request are by using a high order component called withDialogError to provide and open an error dialog when the request returns an error.
Using this approach made it very coupled to the container and Redux because of the way we need to pass data down to the high order component.
When we don't handle errors for a given request, we don't have the data, and it can get us the famous:
Uncaught TypeError: Cannot read property 'a' of undefined
With our ErrorBoundary, it gets this exception and opens a drawer kind of page showing a friendly (but generic) message about the current error. Looking at the fatal errors in Sentry, I understood the correlation (and sometimes causation) with the missing error handling.
I started to redesign the way we handle the errors to remove all the Redux boilerplate and how the error dialog was coupled to the Redux container. Instead of using a high order component, it would be easier to reason about if it was just a declarative component that we add to the page and it receives the correct props to open and show the necessary content and action buttons.
To make the error dialog works properly, I needed to be able to always provide if it is open or not (basically an isError from a request-response), the content (specific for each request/page), and the possibility to refetch/re-request with an action button.
This discovery made me rethink how we handle data fetching - today using Redux - and I started a new exploration looking for new ways to do data fetch stuff, state management, and improve the developer experience of handling errors.
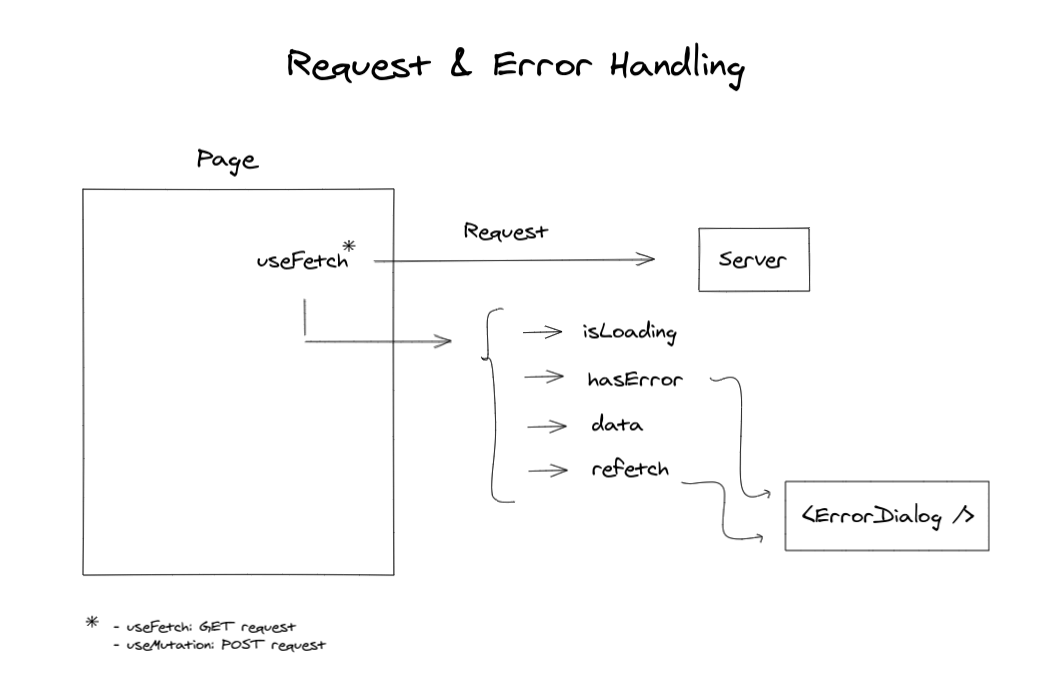
I started by designing the best experience when it comes to data fetching and then I thought of an abstraction to be able to use it in all codebase. But instead of implementing the best abstraction, I started to search for a solution. Well, data fetching is a common challenge in all kinds of frontend applications and we actually have nice alternatives in the community (react-query, swr).
I created some Proofs-of-Concept (PoC) to handle use cases using react-query. The result is pretty interesting. The way react-query handles cache and revalidation and separates client state and server cache is pretty interesting and it also enables us to rethink state management in our frontends. It could be the way we handle data fetching in our PWAs and I started to share this exploration across the organization.
Scale & Culture
"If You Want to Go Fast, Go Alone. If You Want to Go Far, Go Together."
When my manager talked to me about this project, I realized it was a technical leadership role. I was given the opportunity and a lot of autonomy to explore different technical and product issues, understand the pain points that made engineering processes slower and build a vision to make the team move forward.
As I wrote in the beginning, sharing knowledge and transparency were principles I wanted to follow in the entire project. I have a Notion page with everything about the project: roadmap, backlog, goals & principles, documented discoveries, meeting notes, etc. Everything there, open, and easy to access and find information.
Have an open page to give visibility to the entire organization was the first step, but I also wanted to be very intentional about the project. I had the opportunity to talk about what I was working on 3 times a week in the team's daily meeting, I had weekly engineering syncs with the engineering leadership.
For each exploration I did, it was all documented and shared with the team. With the draft idea, I could call a meeting with engineers to explain the exploration, the problem I was working on, and open for discussions and questions.
"The act of asking good questions with good intent opens up a conversation, creating space and safety for others to ask their own questions." - Will Larson
With these meetings, I could make three things happen:
- Give visibility of the problem, possible solutions, and a vision.
- Give space for them to ask or share opinions and be part of the vision.
- And refine the solutions and vision.
As Kevan Lee said: "Transparency starts as a mindset change". I wanted to be intentional in terms of transparency and give them space and accessible documents were the ways I found to make them part of the whole process.
Final words & Resources
I learned a lot throughout this project. It was for sure one of the most challenging projects I did in my career and I had a lot of fun studying, learning, applying my knowledge, thinking in strategy, communicating as a leader, and enjoying the opportunity to work on developer experience and software maintainability.
Throughout the project, I used some resources that I want to share with you all. It's not a prerequisite to manage a project like this, but these resources helped me a lot.
Software Maintainability
- Simple made easy
- Building Resilient Frontend Architecture
- React Query: It’s Time to Break up with your "Global State”
- On composable, modular frontends
- On choosing independence… for a software developer
- Surviving death by complexity
- Embracing simplicity in your engineering team
- Scaling held knowledge to unblock teams and untangle software complexity
- Implementing a plan to clean up technical debt
- Maintaining speed while minimizing risk
Developer Experience
- What is Developer Experience (DX)?
- An Introduction to Developer Experience (DevEx, DX)
- A Conversation about Developer Experience with Lei Zhang
- Why Every Software Team Should Have a Developer Experience Owner (DXO)
- Engineering Productivity: Measure What Matters
- Continuously Integrating Distributed Code at Netflix
- The Importance of a Great Developer Experience
- Measuring and improving the efficiency of software delivery
Engineering Leadership
- Engineering principles: putting our values into practice
- Suckless Philosophy
- Thriving on the Technical Leadership Path
- StaffEng project
- Staff Engineer book
- Learn to never be wrong
- Where to Start
- Building Bridges as a Technical Leader
- Technical Research and Preparation
- The reality of being a Principal Engineer
- What does sponsorship look like?
- What a Senior Staff Software Engineer Actually Does - Part 1
- What a Senior Staff Software Engineer Actually Does - Part 2
- Defining a Distinguished Engineer