A Deep Dive into the TypeScript Compiler Miniature
 Photo by Jez Timms
Photo by Jez TimmsAs you may know, I've been studying compilers. A lot. For the past month, I've been learning more about the TypeScript compiler, reading its source code, and implementing some of the exercises from the mini-typescript.
In this post, I want to cover some of my learnings while reading the TypeScript compiler miniature's source code and implementing the exercises.
I divided this series into three parts and the following posts to cover everything about the TypeScript compiler. The first two were already published and you can take a look at them here:
- A High Level Architecture of the TypeScript compiler
- JavaScript scope, Closures, and the TypeScript compiler
And now, in this post, I will cover different features of the mini-typescript and how they are implemented. For the exercises I implemented in the project, I will write new articles in the following posts of the series.
By the way, I think it's a good idea to read the first two posts before reading this if you don't know how compilers and the TypeScript compiler work. The first one will give a good overview of the steps of the compiler and how each piece fits together. The second one will talk about closures and how they are used to make the compiler more modular and easier to change and manage its state.
With the two pieces, I think you'll be ready to read how some of the features of the TypeScript miniature are implemented.
Let's go!
Before going into each feature, I just wanted to illustrate how the compiler structures each step. Basically, how it represents tokens in the lexer step, AST nodes in the parser, variable and type declarations in the binder, and types in the type checker.
Representing tokens
The idea of a lexer is to go through character by character and produce a new token. It receives the source code as a string and starts from position 0. In this simplest version, it has states like pos as the position of the current character it's analyzing, token as the token type of the produced token, and text that could be the name of an identifier (e.g. age from var age = 1;), a number value (e.g. 1), a keyword (e.g. var), or a string value (e.g. "string").
As an example, if we have this source code
var age: number = 1;
The lexer will produce this list of tokens
var:text: “var”token: “Var”
age:text: “age”token: “Identifier”
::text: undefinedtoken: “Colon”
number:text: “number”token: “Identifier”
=:text: undefinedtoken: “Equals”
1:text: “1”token: “NumericLiteral”
;:text: undefinedtoken: ”Semicolon”
In a visible way, it should look like this
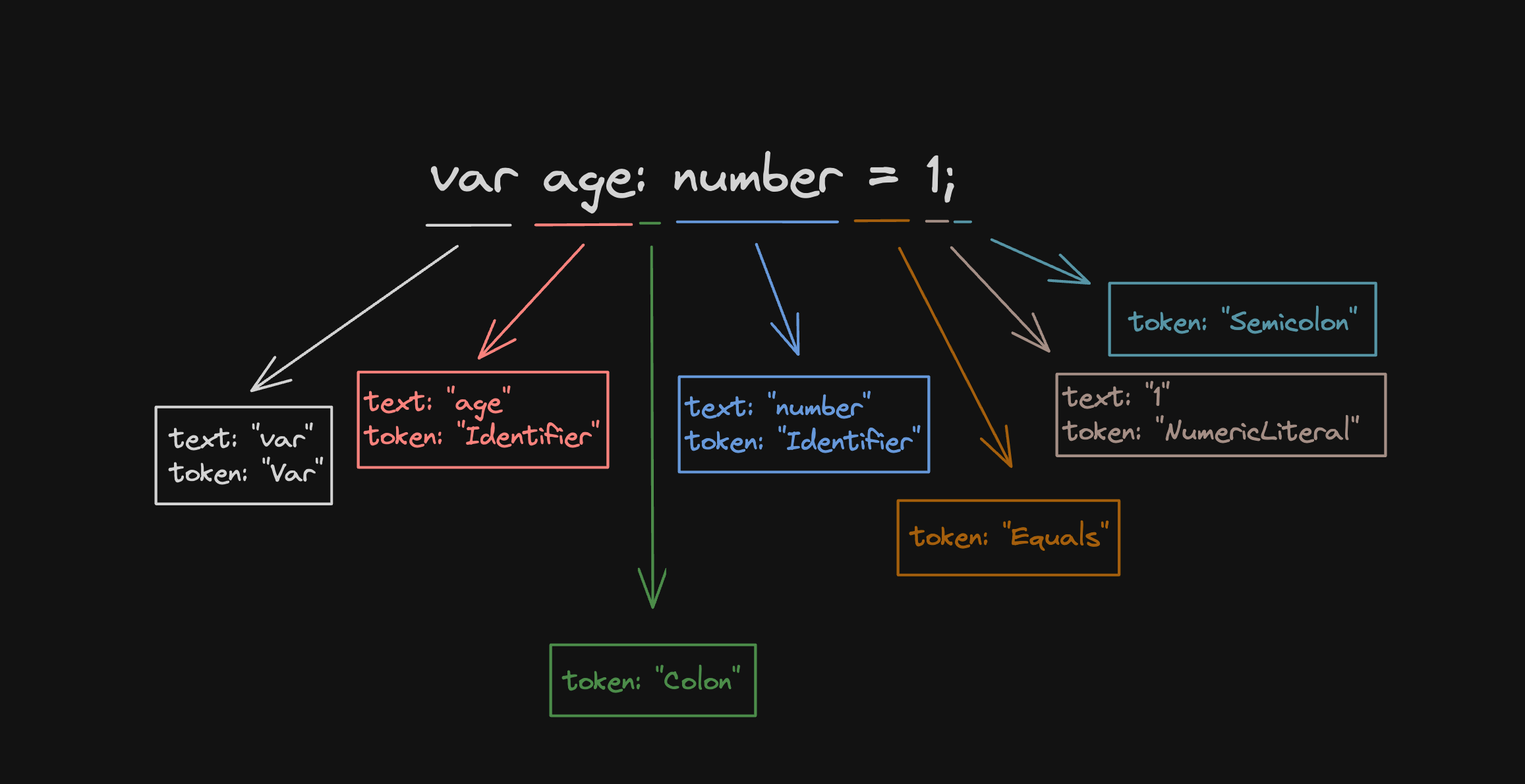
Representing AST nodes
AST nodes are basically Statements. They can be ExpressionStatement, Var, TypeAlias, or EmptyStatement.
The type looks like a union of all these types
type Statement = ExpressionStatement | Var | TypeAlias | EmptyStatement;
To have an idea of how AST nodes can be structured, let's take ExpressionsStatement as an example and see its data types and the transformation from source code to AST node.
The ExpressionStatement can be different expressions: Identifier, NumericLiteral, Assignment, or StringLiteral.
type Expression = Identifier | NumericLiteral | Assignment | StringLiteral;
Each node can have different “attributes”. For example,
NumericLiteralandStringLiteralcan have avalueattribute. ForNumericLiteral, it's a number and forStringLiteral, it's a string.- The
Identifierhas atextattribute, that's its name. - The
Assignmenthas thenameand thevalue.
Let's see how we can represent each of these nodes — their data types
interface Identifier {
kind: Node.Identifier;
text: string;
pos: number;
}
interface Assignment {
kind: Node.Assignment;
name: Expression;
value: Expression;
pos: number;
}
interface NumericLiteral {
kind: Node.NumericLiteral;
value: number;
pos: number;
}
interface StringLiteral {
kind: Node.StringLiteral;
value: string;
pos: number;
}
This is already a good node representation of each.
Let's now see examples of each node.
An identifier with name name:
// source code:
// name;
const identifier = {
kind: 'Identifier',
text: 'name',
pos: 0,
};
An assignment with name age and value 1:
// source code:
// age = 1;
const assignment = {
kind: 'Assignment',
name: {
// an identifier is an expression
kind: 'Identifier',
text: 'age',
pos: 0,
},
value: {
// a numeric literal is an expression
kind: 'NumericLiteral',
value: 1,
pos: 1,
},
pos: 0,
};
A numeric literal:
// source code:
// 1;
const numericLiteral = {
kind: 'NumericLiteral',
value: 1,
pos: 0,
};
A string literal:
// source code:
// 'hello';
const stringLiteral = {
kind: 'StringLiteral',
value: 'hello',
pos: 0,
};
This already gives us a nice overview of how we can represent the source code in AST nodes. In the feature sections, we will dive deeper into each feature and see how this is used in the following steps like the binder and the type checker.
Binder: storing the type and variable declarations
Here in the binder, one of its responsibilities is storing declarations of types and variables. The compiler stores it in a data structure and the statements or AST nodes can be “fetched” later on.
The data structure the compiler uses to store these declarations is a Map, a key-value data structure, where the key is the name of the identifier (name of the type or the variable) and the value is a list of statements.
The value is a list of statements because we can do this:
type test = string;
var test = 'string';
For the same test identifier's name, we can have two different statements, and the best way to do it is to store them in a list of declarations. Later on, if we want to access one of the declarations, we need to pass the type of statement we're looking for, if it's a type or a variable.
For the above example, we would have the statements stored like this in the Map:
Map(1) {
'test' => [
// The Variable AST node
{
kind: Node.Var,
name: {
kind: 'Identifier',
text: 'test',
},
init: {
kind: 'StringLiteral',
value: 'string',
},
},
// The Type Alias AST node
{
kind: Node.TypeAlias,
name: {
kind: 'Identifier',
text: 'test',
},
init: {
kind: 'Identifier',
text: 'string',
},
}
]
}
For the same identifier name test, it has a list of declarations, a variable statement and a type alias statement,
So now, the compiler can use this data structure and query the statements. To resolve it, we pass the name and the type of the statement we are looking for.
const symbol = locals.get(name);
if (symbol?.declarations.some((d) => d.kind === type)) {
return symbol;
}
What's happening here?
- It gets the symbol based on the
name - and then it tries to find the declaration statement based on the
type, wheretypecan be eitherVarorTypeAlias.
For every AST node created from the parser, the binder will handle them and figure out if it should add it or not to the Map. And then the type checker can resolve the statement whenever it needs to check the types. This is valuable when the type checker reaches the
Values in the type checker
In general, the type checker will do two things: one is to generate a type structure for each node and the second is to compare these types.
For expressions like strings and numbers, it should return the stringType and numberType. The shape of these types is simple:
const stringType: Type = { id: 'string' };
const numberType: Type = { id: 'number' };
For statements like variable declaration and assignment, it will compare the returned type from the value and the identifier's type. If you have this variable declaration example:
var num: number = '123';
⎸
↳ Type 'string' is not assignable to type 'number'.
It should provide a type error like it was illustrated above, right? The type checker should only compare these two nodes: the identifier num with the type NumericLiteral and the expression '123' with the type StringLiteral. We clearly see a mismatch between these two types and the compiler attaches this new error to the “store of errors” or a Map of errors.
For assignments, it works pretty much the same way:
var num: number = 123;
num = '123';
⎸
↳ Type 'string' is not assignable to type 'number'.
But now it needs to go to the binder and ask for the identifier num. It will try to resolve it, get the symbol, and generate the related type. Then it just compares the generated type with the value type.
We are going to see more of this in-depth later on in cases like variable declarations and assignments.
Now that we understand how each part of the compiler represents characters, tokens, and AST nodes, let's get some features and unpack how they were implemented.
We go from the lexer, passing to the parser and binder, and ending in the type checker.
NumericLiteral: handling numbers
We first start with the lexer. There it will scan characters and transform them into tokens. For NumericLiterals, it needs to read numbers from the source code. This is what we'll be looking for.
The first part is to check if the current character is a possible number.
if (/[0-9]/.test(s.charAt(pos))) {
// ...
}
Using regular expressions, we can accomplish this. Check if the character in the position pos passes the regex test for any number from 0 to 9. If this character is the one, we know it's a NumericLiteral.
Numbers can be just one digit or more. To make sure it gets the entire number, we should keep scanning until we “finish” the number.
Now I want to present to you the function scanForward. It keeps scanning the source code and moving forward if the predicate is true.
function scanForward(pred: (x: string) => boolean) {
while (pos < s.length && pred(s.charAt(pos))) pos++;
}
We also make sure we stop the loop if it reaches the end of the source code. The pred is just a predicate function, it will receive the current character and return a boolean, if the character passes the check or not.
In this case, the predicate is if the current character is a number.
function isNumber(c: string) {
return /[0-9]/.test(c);
}
So if we run this code:
scanForward(isNumber);
It will keep scanning forward until it reaches the end of the number or the end of the source code. That's it. Before any operation starts in the lexer, we store the start position. When it finishes scanning the entire number, the position pos goes to the last index of the number. To get the text, we should just slice that:
text = s.slice(start, pos);
And to finish it, the token should be a NumericLiteral.
token = Token.NumericLiteral;
Now that the compiler finished the “tokenization”, we are now in the parsing process.
Remember that the parser has an instance of the lexer? The instance has functions like scan, token, text, and pos.
Before start understanding the parser, let's recall the structure we want to generate for the NumericLiteral. You should remember that a number is an expression, so the structure will look like this:
{
kind: Node.ExpressionStatement;
pos: number;
expr: {
kind: Node.NumericLiteral;
value: number;
pos: number;
}
}
We should have a statement, more specifically, an expression statement, and the expression is a number. The number will have NumericLiteral as its kind, the value (e.g. the number 1 will be the value if the source code is 1;), and the position pos of the statement.
The parser tries to parse all kinds of statements before an expression, if it doesn't parse anything, it tries parsing the expression. This is the returned value when parsing the statements:
{ kind: Node.ExpressionStatement, expr: parseExpression(), pos };
When parsing the expression, we want to see if it can parse a number, so it uses a function called tryParseToken. That's a very interesting function:
function tryParseToken(expected: Token) {
const ok = lexer.token() === expected;
if (ok) {
lexer.scan();
}
return ok;
}
If it's the expected token, in this case, the Token.NumericLiteral, it will scan and return if it's the expected one. That's interesting because it can be used like this:
if (tryParseToken(Token.NumericLiteral)) {
return { kind: Node.NumericLiteral, value: +lexer.text(), pos };
}
That's exactly what we need to create the number AST node.
- It tries to parse the token
Token.NumericLiteraland the current token is the expected one - It just returns the
NumericLiteralAST node: take a look that it “cast” the text into a number with the+sign (take a look at unary plus +)
And now we have the full AST node for the expression statement.
The binder doesn't do anything regarding the number as we learned that one of its responsibilities is to store the variable and type declarations.
The type checker just produces a number type as we've seen early on. This part is super straightforward. It checks every statement, so when it gets to the expressions and the current expression is a Node.NumericLiteral, it just returns a numberType, which is this structure:
const numberType: Type = { id: 'number' };
This type will be helpful and used to compare the types between statements and check if we have any type mismatch, or as we usually say a "type error".
Var: handling variable declarations
As we've seen before. This is an important type as it will be used for the comparison of types in other checks.
Let's see another statement that's even more interesting. We'll be talking about the variable declaration. Let's understand how the compiler parses and type checks this source code:
var num: number = 1;
In the tokenization process, let's start with the simplest tokens: Equals (=), Semicolon (;), and Colon (:).
This part is straightforward. If the current character is one of these mentioned earlier, we just assign the right token for that. The code will look pretty much like this:
case '=':
token = Token.Equals;
break;
case ';':
token = Token.Semicolon;
break;
case ':':
token = Token.Colon;
break;
These tokens will be helpful to parse the entire variable declaration. For example, at least in the first version, the declaration will always expect the Equals token after the identifier or the typename.
Now we need to create tokens for the var, the name identifier (the name of the variable), and the typename identifier (the name of the type).
All of them are “alphabetical characters” and this is the first hint. Whenever the current character is an alphabetical char, we know we can be scanning a keyword or an identifier. Both will be implemented in the same way.
This looks pretty similar to the NumericLiteral we've seen before:
if (/[_a-zA-Z]/.test(s.charAt(pos))) {
// ...
}
But now we are looking at alphabetical characters rather than numbers. We even do scanning the same way using the scanForward we used before. Identifier can have numbers in its name, so the predicate will be if the character is an alphanumeric char. Here it's:
function isAlphanumerical(c: string) {
return /[_a-zA-Z0-9]/.test(c);
}
Let's scan forward all the way to the end of the keyword or the identifier:
scanForward(isAlphanumerical);
The text will be a simple slice between the start position to the end position:
text = s.slice(start, pos);
And the token is when we separate what's a keyword and what's an identifier. The whole idea is: if the text belongs to the “keywords” list, it's a keyword, if not, it's an identifier. This is the “list”, or better, the object:
const keywords = {
function: Token.Function,
var: Token.Var,
type: Token.Type,
return: Token.Return,
};
To handle this logic, we use a simple ternary together with the in operator:
token =
text in keywords ? keywords[text as keyof typeof keywords] : Token.Identifier;
That's the whole implementation:
if (/[_a-zA-Z]/.test(s.charAt(pos))) {
scanForward(isAlphanumerical);
text = s.slice(start, pos);
token =
text in keywords
? keywords[text as keyof typeof keywords]
: Token.Identifier;
}
And that's it, the lexer part for the whole variable declaration is done.
Again, this is how it looks like:
Now that we have all the tokens for the variable declaration, let's parse them into an AST node. In the end, it will look like this:
{
"kind": "Var",
"name": {
"kind": "Identifier",
"text": "num"
},
"typename": {
"kind": "Identifier",
"text": "number"
},
"init": {
"kind": "NumericLiteral",
"value": 1
}
}
This is an AST node with type Var, the name is an identifier num, the typename is also an identifier but a number, and the init is the initial value expression, in this case, a NumericLiteral with value 1.
This is the main logic to parse a variable declaration:
if (tryParseToken(Token.Var)) {
const name = parseIdentifier();
const typename = tryParseToken(Token.Colon)
? parseIdentifier()
: undefined;
parseExpected(Token.Equals);
const init = parseExpression();
return { kind: Node.Var, name, typename, init, pos };
}
There are a lot of things going on here, let's unpack it.
First, we use tryParseToken to see if it's an actual Token.Var token. If it's, we know how this structure should be. The first part of this node is the name. It should be an identifier, so it calls the parseIdentifier function to parse it.
To create the AST node regarding the identifier, it tries to parse the token Token.Identifier and it returns the whole structure, like this:
if (tryParseToken(Token.Identifier)) {
return { kind: Node.Identifier, text: lexer.text(), pos };
}
The second part of the Var node is the typename. But types are optional in TypeScript, so it tries to parse the Token.Colon token, if it passes, we expect to parse the type, which's an identifier too, so it just calls parseIdentifier again. If it doesn't have the Token.Colon token, the typename will be undefined. This gives the optionality feature for TypeScript.
The third part is the = token. In JavaScript, it is totally possible to write variable declarations without an initial value, like this:
var num;
But in this initial implementation of the compiler miniature, it'll require it to have the assignment and the initial value.
To make it a requirement, it just needs to expect the = token. We'll use a function called parseExpected:
function parseExpected(expected: Token) {
if (!tryParseToken(expected)) {
error(
lexer.pos(),
`parseToken: Expected ${Token[expected]} but got ${Token[lexer.token()]}`,
);
}
}
If it doesn't parse the expected token, the = token in this case, it will add a new error to the compiler's Map of errors. If it parses, it just moves forward to the next token. And the next token is an expression.
An expression being a NumericLiteral is already implemented so we covered everything for that specific source code. We can see the implementation of different types of expressions like StringLiterals and Identifiers, but this will be a topic for future posts in this series.
We're now missing the implementation of the binder and the type checker for variables.
The binder can be intimidating at first but the code is super simple. If you've already practiced and solved algorithm problems, you probably already came across algorithms that you need to add values to a Map. The binder is pretty similar:
- Get a symbol from the
Map - If it has the key, add a new value to the list
- If it doesn't, add the first value to the list
Let's see the whole code first:
if (statement.kind === Node.Var || statement.kind === Node.TypeAlias) {
const symbol = locals.get(statement.name.text);
if (symbol) {
const other = symbol.declarations.find((d) => d.kind === statement.kind);
if (other) {
error(
statement.pos,
`Cannot redeclare ${statement.name.text}; first declared at ${other.pos}`,
);
} else {
symbol.declarations.push(statement);
if (statement.kind === Node.Var) {
symbol.valueDeclaration = statement;
}
}
} else {
locals.set(statement.name.text, {
declarations: [statement],
valueDeclaration: statement.kind === Node.Var ? statement : undefined,
});
}
}
Let's unpack the idea of the statement binding.
In this initial implementation, we are handling only Node.Var and Node.TypeAlias.
The first step is to try to get a symbol from the Map. It queries the symbol based on the statement name.
const symbol = locals.get(statement.name.text);
- If it does have a symbol in the
Map, we should add a new statement to the declarations list (a couple more things we are going to see) - If it doesn't, we should just set the statement as the first declaration in the declarations list
Before adding a new statement to a given symbol, we should see if the source code is trying to redeclare the same variable or the same type again because we should get an error if we write code like this:
var a = 1;
var a = 2;
In real JavaScript, var allows us to redeclare the same name. In the following posts of the series, we'll see a new implementation of the Let statement and how it shouldn't allow redeclaring the same statement. But in this first implementation, var won't allow it.
To add this rule to the statement binding, the binder needs to look at the declarations list of the current symbol and check if there's a statement with the same kind as the current statement.
In the source code above, it adds the first statement to the declarations list with the key as a. When it goes to the second statement, it tries to find any other statement with the same kind, “var” in this case, and it finds it. We do it using the Array's find method.
const other = symbol.declarations.find((d) => d.kind === statement.kind);
If we find it, we know we should report an error. And this is done:
if (other) {
error(
statement.pos,
`Cannot redeclare ${statement.name.text}; first declared at ${other.pos}`,
);
}
If we couldn't find it, the binder just follows the same flow: add the new statement to the list of declarations.
I won't talk too much about valueDeclaration but this will be super useful in the type checking process for identifier and assignment expressions.
When we talked about the type checker early on, I wrote that expressions return their own type, so we can use them to compare, see if it has any type mismatch, and report an error if that's the case.
In variable declarations, we also should return their own type, but we can have two different scenarios:
// variable without a typename
var num = 1;
// variable with a typename
var num: number = 1;
Variables with and without the typename. The logic is very simple.
- If it doesn't have the typename, it should just return the type related to the value expression. In the above example, it should return the type related to
1, in other words, it should return thenumberType - If it does have the typename, it should return the typename's type. In the above example, it should return the type related to
number, in other words, it should return thenumberType
Here's the implementation of this logic
function checkStatement(statement: Statement): Type {
switch (statement.kind) {
case Node.Var:
const i = checkExpression(statement.init);
if (!statement.typename) {
return i;
}
const t = checkType(statement.typename);
if (t !== i && t !== errorType)
error(
statement.init.pos,
`Cannot assign initialiser of type '${typeToString(
i,
)}' to variable with declared type '${typeToString(t)}'.`,
);
return t;
// ...
}
}
Let's unpack this code:
- First, it checks the
initexpression. It can be related to any expression. One example is if the expression is1, it will return thenumberType - Then it checks if there's a typename. If not, it should just return the type related to the
initexpression - If there's a typename, it will get the type related to it. In the case of an identifier like
number, it will check its type and return thenumberType - If the types produced before don't match, we have a “type error” and it reports the error to the
Mapof errors - In the end, it will return the type related to the typename
If there's no typename, it favors the value or expression type. If there's a typename, it favors the typename type.
For variable declarations, we are always comparing and checking if the types match and return the favored type.
Assignment: handling assignment operations
Let's first see a simple example of an assignment:
var num: number = 1;
// assigning `2` to `num`
num = 2;
If we separate the tokens that are part of this source code, we get:
num: anIdentifier=: anEquals2: anExpression, more specifically aNumericLiteral
You probably noticed we don't need to implement anything new in the lexer as we already have all the tokens in place, and that's great! Let's go straight to the parser then.
As you already know, the Assignment node is an expression statement. For this source code:
num = 2;
We get this AST node:
{
"kind": "ExpressionStatement",
"expr": {
"kind": "Assignment",
"name": {
"kind": "Identifier",
"text": "num"
},
"value": {
"kind": "NumericLiteral",
"value": 2
}
}
}
It's
- An expression statement
- The expression is an
Assignment - The assignment is separated into two pieces:
name: usually an identifier, in this case, the textnumvalue: usually an expression, in this case, the numeric literal2
Let's parse it then.
When parsing an expression, we have a function to handle that. It's called parseExpression:
function parseExpression(): Expression {
const pos = lexer.pos();
const e = parseIdentifierOrLiteral();
if (e.kind === Node.Identifier && tryParseToken(Token.Equals)) {
return { kind: Node.Assignment, name: e, value: parseExpression(), pos };
}
return e;
}
The first step is to parse an identifier or a literal (it can be a numeric or a string literal). It will always return an expression. If it returns an identifier and then the current token is the Equals, we know that's an Assignment expression.
Now we know it's an assignment and we have the identifier. The only thing missing is the value expression. And we just need to call parseExpression again and it will parse it for us.
That's interesting because it covers both possible scenarios:
- when the value expression is a literal, e.g.
1or'string' - and when the value expression is an identifier, e.g.
num, as you may know, we can assign the value of a variable to another, like the following example
var num = 1;
var n = 2;
// assigning the value of
// an identifier (variable)
// into another identifier (another variable)
n = num;
And that's it! We have a working AST node for the Assignment.
In the binder, the compiler just handles Var and TypeAlias nodes, so we don't need to do anything else there.
The whole idea of type checking the assignment expression is to type check expressions in general because it should get the type related to the identifier and related to the value expression, and then compare them.
This is how we translate the logic above into code.
const v = checkExpression(expression.value);
const t = checkExpression(expression.name);
if (t !== v)
error(
expression.value.pos,
`Cannot assign value of type '${typeToString(
v,
)}' to variable of type '${typeToString(t)}'.`,
);
return t;
What does it do?
- check the value expression
- check the identifier expression
- compare them and see if they match. If not, report an error to the
Mapof errors - and return the identifier type
But what's this checkExpression function? This is the whole function
function checkExpression(expression: Expression): Type {
switch (expression.kind) {
case Node.Identifier:
const symbol = resolve(module.locals, expression.text, Node.Var);
if (symbol) {
return checkStatement(symbol.valueDeclaration!);
}
error(expression.pos, 'Could not resolve ' + expression.text);
return errorType;
case Node.NumericLiteral:
return numberType;
case Node.StringLiteral:
return stringType;
case Node.Assignment:
const v = checkExpression(expression.value);
const t = checkExpression(expression.name);
if (t !== v)
error(
expression.value.pos,
`Cannot assign value of type '${typeToString(
v,
)}' to variable of type '${typeToString(t)}'.`,
);
return t;
}
}
It seems a bit intimidating but it's not that hard to understand. Let's unpack it.
NumericLiteral and StringLiteral aren’t difficult to understand. We've seen them before. They just return simple types: numberType and stringType.
When calling the checkExpression in the assignment block, we can fall into three possibilities:
IdentifierNumericLiteralStringLiteral
The type for the expression's name will probably be an identifier type. And the type of the expression's value can fall into these three categories. Let's see some examples:
var num: number = 1;
var s: string = 'string';
var n: number = num;
- The first line falls down into the name being an identifier and the value expression a numeric literal
- The second line falls down into the name being an identifier and the value expression a string literal
- The third line falls down into the name being an identifier and the value expression also an identifier
The most interesting part of the expression type checking is the case of an identifier expression.
Whenever it needs to type check an identifier, it first uses the resolve function to query a symbol from the binder's Map.
If it finds the symbol, it checks the value declaration and returns its related type.
If it doesn't find any symbol, it couldn't resolve it and it should report a new error to the Map of errors.
TypeAlias: handling named types
If we untangle the type alias, we can see we already implemented everything about it in the lexer phase.
type age = number;
type: it's part of the keywordsage: it's an identifiernumber: also an identifier
That's the structure of a type alias: the type keyword, the name of the type (identifier), the equals token, and the typename (identifier).
if (tryParseToken(Token.Type)) {
const name = parseIdentifier();
parseExpected(Token.Equals);
const typename = parseIdentifier();
return { kind: Node.TypeAlias, name, typename, pos };
}
We only start creating the type alias AST node if we can parse the Token.Type token.
And this is an example of a node created in the parsing phrase:
{
"kind": "TypeAlias",
"name": {
"kind": "Identifier",
"text": "age"
},
"typename": {
"kind": "Identifier",
"text": "number"
}
}
This is the structure of the source code we saw above.
In the binder, we don't really need to implement anything else because it was already taken care of as it handles Var and TypeAlias statements. Type alias statements will follow the same flow and logic as the variable declarations.
One interesting point here is that we can't redeclare variables or redeclare types, but we can have a type and a variable with the same name. And it's already implemented the binder.
Because we already implemented most of the type checker, checking type aliases became super easy. One of the things we need to do is to add this line of code:
case Node.TypeAlias:
return checkType(statement.typename);
If the statement is a TypeAlias, we should check the type of typename. Calling checkType, it will fall into three possibilities:
typenameasNumericLiteral: it should return anumberTypetypenameasStringLiteral: it should return astringTypetypenameasTypeAlias: it should resolve a type alias symbol from theMapof declarations. If it finds the symbol, it callscheckTypeagain but now with thetypenameof the declaration it found in theMapbuilt in the binder
This is the whole code:
function checkType(name: Identifier): Type {
switch (name.text) {
case 'string':
return stringType;
case 'number':
return numberType;
default:
const symbol = resolve(module.locals, name.text, Node.TypeAlias);
if (symbol) {
return checkType(
(
symbol.declarations.find(
(d) => d.kind === Node.TypeAlias,
) as TypeAlias
).typename,
);
}
error(name.pos, 'Could not resolve type ' + name.text);
return errorType;
}
}
Just a tiny additional piece of info: if the resolve couldn't find the type alias typename in the Map of declarations, it should report an error in the Map of errors.
If the source code is like this:
type N = number;
type S = string;
It will fall into the two first possibilities: it returns the type for typename and they are numberType and stringType.
For a source code like this:
type N = number;
type Num = N;
It will fall into the third possibility, where N is a TypeAlias and we should query it in the Map of declarations we built in the binder. Resolving it, we find that its typename is number and then it returns numberType for the Num type alias.
Final words
In this piece of content, my goal was to show two main things:
- The data structures used in each phase of the compiler
- How some features are implemented to understand each phrase more in-depth
I hope it can be a nice source of knowledge to understand more about the TypeScript compiler and compilers in general. This was a full dump of my last 3 months I've been studying, researching, and working on the TS compiler miniature.
This is a series of posts about compilers and if you didn't have the chance to see the previous two posts, take a look at them:
- A High Level Architecture of the TypeScript compiler
- JavaScript scope, Closures, and the TypeScript compiler
For additional content on compilers and programming language theory, have a look at the Programming Language Design tag and the Programming Language Research repo.
Thanks to Nathan Sanders for the immense support and discussions.
Resources
- TypeScript codebase
- How the TypeScript Compiler Compiles
- mini-typescript
- TypeScript Compiler Manual
- A High Level Architecture of the TypeScript compiler
- JavaScript scope, Closures, and the TypeScript compiler